This page contains a list of my publications, in reverse chronological order. You can find other useful catalogs of my publications on my Google Scholar Index and ACM Author Profile pages.
-
Hardware-Accelerated Encrypted Execution of General-Purpose Applications. In Proceedings on Privacy Enhancing Technologies (PoPETs) 2025.
-
Task-Based Tensor Computations on Modern GPUs. In ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI) 2025.
-
Composing Distributed Computations Through Task and Kernel Fusion. In Proc. 30th ACM Int'l Conf. on Architectural Support for Programming Languages and Operating Systems (ASPLOS) 2025.
-
Automatic Tracing in Task-Based Runtime Systems. In Proc. 30th ACM Int'l Conf. on Architectural Support for Programming Languages and Operating Systems (ASPLOS) 2025.
-
CUDASTF: Bridging the Gap Between CUDA and Task Parallelism. In Proc. of the Int'l Conference on Supercomputing (SC) 2024.
-
Legate Sparse: Distributed Sparse Computing in Python. In Proc. of the Int'l Conference on Supercomputing (SC) 2023.
-
Graphene: An IR for Optimized Tensor Computations on GPUs. In Proc. 28th ACM Int'l Conf. on Architectural Support for Programming Languages and Operating Systems, Volume 3 (ASPLOS 2023), March 2023.
-
Visibility Algorithms for Dynamic Dependence Analysis and Distributed Coherence. In Proc. 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming (PPoPP '23), February 2023.
-
GPU-Initiated On-Demand High-Throughput Storage Access in the BaM System Architecture. In Proc.28th ACM Int'l Conf. on Architectural Support for Programming Languages and Operating Systems, Volume 2 (ASPLOS 2023), January 2023.
-
Stream-K: Work-centric Parallel Decomposition for Dense Matrix-Matrix Multiplication on the GPU. arXiv:2301.03598 [cs.DS], January 2023.
-
Efficient Sparsely Activated Transformers. arXiv:2208.14580 [cs.LG], August 2022.
-
GPU-Initiated On-Demand High-Throughput Storage Access in the BaM System Architecture. arXiv:2203.04910 [cs.DC], March 2022.
-
Supercomputing in Python With Legate. Computing in Science & Engineering, vol. 23, no. 04, pp. 73-79, 2021.
-
Scaling Implicit Parallelism via Dynamic Control Replication. In Proc. Principles and Practices of Parallel Programming (PPoPP), Feb 2021.
-
A Programmable Approach to Neural Network Compression. IEEE Micro, vol. 40, no. 5, pp. 17-25, Sep/Oct 2020.
-
Legate NumPy: Accelerated and Distributed Array Computing. In Proc. Int'l Conference for High Performance Computing, Networking, Storage, and Analysis (SC '19), November 2019.
-
GPU-Accelerated Atari Emulation for Reinforcement Learning. arXiv:1907.08467v1 [cs.LG], July 2019.
-
Throughput-oriented GPU memory allocation. In Proc. 24th Symposium on Principles and Practice of Parallel Programming (PPoPP '19), February 2019.
-
Dynamic tracing: memoization of task graphs for dynamic task-based runtimes. In Proc. Int'l Conference for High Performance Computing, Networking, Storage, and Analysis (SC '18), November 2018.
-
AdaBatch: Adaptive Batch Sizes for Training Deep Neural Networks. ArXiv:1712.02029, December 2017.
-
Parallel Depth-First Search for Directed Acyclic Graphs. In Proc. Seventh Workshop on Irregular Applications: Architectures and Algorithms (IA3'17), November 2017.
-
Designing a Tunable Nested Data-Parallel Programming System. ACM Trans. Archit. Code Optim. 13(4), December 2016.
-
Merge-based Parallel Sparse Matrix-vector Multiplication. In Proc. Int'l Conference for High Performance Computing, Networking, Storage and Analysis (SC'16), November 2016.
-
Architecture-Adaptive Code Variant Tuning. In Proc. ASPLOS '16, April 2016.
-
Single-pass Parallel Prefix Scan with Decoupled Look-back. NVIDIA Technical Report NVR-2016-002, March 2016.
-
Parallel Methods for Verifying the Consistency of Weakly-Ordered Architectures. In Proc. PACT 2015, October 2015.
-
Optimizing Sparse Matrix Operations on GPUs Using Merge Path. In Proc. IPDPS 2015, May 2015.
-
High-Performance and Scalable GPU Graph Traversal. ACM Trans. Parallel Comput. 1(2), February 2015.
-
Work-Efficient Parallel GPU Methods for Single Source Shortest Paths. Proc. IPDPS 2014, May 2014.
-
Nitro: A Framework for Adaptive Code Variant Tuning. Proc. IPDPS 2014, May 2014.
-
Red Fox: An Execution Environment for Relational Query Processing on GPUs. Proc. CGO 2014, Feb 2014.
-
A Decomposition for In-place Matrix Transposition. Proc. PPoPP 2014, February 2014..
-
Designing a Unified Programming Model for Heterogeneous Machines. Proc. SC12, November 2012.
-
Policy-based Tuning for Performance Portability and Library Co-optimization. Proc. Innovative Parallel Computing (InPar 2012), May 2012.
-
Efficient Parallel Merge Sort for Fixed and Variable Length Keys. Proc. Innovative Parallel Computing (InPar 2012), May 2012.
-
Scalable GPU Graph Traversal. Proc. PPoPP 2012, February 2012..
-
Copperhead: Compiling an embedded data parallel language. Proc. PPoPP 2011, February 2011.
-
Implementing sparse matrix-vector multiplication on throughput-oriented processors. Proc. SC09, November 2009.
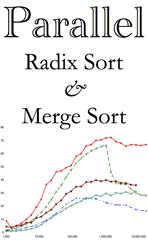
|
N. Satish, M. Harris, and M. Garland.
Designing efficient sorting algorithms for manycore GPUs.
Proc. 23rd IEEE Int’l Parallel & Distributed Processing
Symposium, May 2009. To appear.
[Preprint]
We describe the design of high-performance parallel radix sort and merge sort routines for manycore GPUs, taking advantage of the full programmability offered by CUDA. Our radix sort is the fastest GPU sort and our merge sort is the fastest comparison-based sort reported in the literature. Our radix sort is up to 4 times faster than the graphics-based GPUSort and greater than 2 times faster than other CUDA-based radix sorts. It is also 23% faster, on average, than even a very carefully optimized multicore CPU sorting routine. To achieve this performance, we carefully design our algorithms to expose substantial fine-grained parallelism and decompose the computation into independent tasks that perform minimal global communication. We exploit the high-speed on-chip shared memory provided by NVIDIA’s GPU architecture and efficient data-parallel primitives, particularly parallel scan. While targeted at GPUs, these algorithms should also be well-suited for other manycore processors. | |

|
C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, and D. Manocha.
Fast BVH construction on GPUs,
Proc. Eurographics 2009, March 2009. To appear.
[PDF]
[Movie (AVI)]
[Details]
We present two novel parallel algorithms for rapidly constructing bounding volume hierarchies on manycore GPUs. The first uses a linear ordering derived from spatial Morton codes to build hierarchies extremely quickly and with high parallel scalability. The second is a top-down approach that uses the surface area heuristic (SAH) to build hierarchies optimized for fast ray tracing. Both algorithms are combined into a hybrid algorithm that removes existing bottlenecks in the algorithm for GPU construction performance and scalability leading to significantly decreased build time. The resulting hierarchies are close in to optimized SAH hierarchies, but the construction process is substantially faster, leading to a significant net benefit when both construction and traversal cost are accounted for. Our preliminary results show that current GPU architectures can compete with CPU implementations of hierarchy construction running on multicore systems. In practice, we can construct hierarchies of models with up to several million triangles and use them for fast ray tracing or other applications. | |

|
J. Jin, M. Garland, and E. A. Ramos.
MLS-based scalar fields over triangle meshes and their
application in mesh processing.
Proceedings of the ACM Symposium on Interactive 3D Graphics and
Games, Feb. 2009. To appear.
A novel technique that uses the Moving Least Squares (MLS) method to interpolate sparse constraints over mesh surfaces is introduced in this paper. Given a set of constraints, the proposed technique constructs, directly on the surface, a smooth scalar field that interpolates or approximates the constraints. Three types of constraints: point-value, point-gradient and iso-contour, are introduced to provide flexible control of the scalar field design. Furthermore, the framework also provides the user control over the region of influence and rate of influence decrease of the constraints, through parameter adjustment. We demonstrate that the scalar fields resulted from this framework can be used in several mesh applications such as skin deformation, region selection and curve drawing. | |
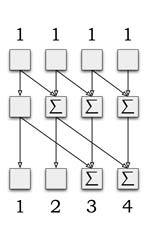
|
S. Sengupta, M. Harris, and M. Garland.
Efficient parallel scan algorithms for GPUs.
NVIDIA Technical Report NVR-2008-003, December 2008
[PDF]
Scan and segmented scan algorithms are crucial building blocks for a great many data-parallel algorithms. Segmented scan and related primitives also provide the necessary support for the flattening transform, which allows for nested data-parallel programs to be compiled into flat data-parallel languages. In this paper, we describe the design of efficient scan and segmented scan parallel primitives in CUDA for execution on GPUs. Our algorithms are designed using a divide-and-conquer approach that builds all scan primitives on top of a set of primitive intra-warp scan routines. We demonstrate that this design methodology results in routines that are simple, highly efficient, and free of irregular access patterns that lead to memory bank conflicts. These algorithms form the basis for current and upcoming releases of the widely used CUDPP library. | |
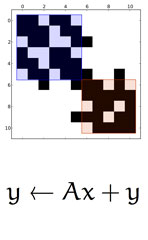
|
N. Bell and M. Garland.
Efficient sparse matrix-vector multiplication on CUDA.
NVIDIA Technical Report NVR-2008-004, December 2008.
[PDF]
[Online]
The massive parallelism of graphics processing units (GPUs) offers tremendous performance in many high-performance computing applications. While dense linear algebra readily maps to such platforms, harnessing this potential for sparse matrix computations presents additional challenges. Given its role in iterative methods for solving sparse linear systems and eigenvalue problems, sparse matrix-vector multiplication (SpMV) is of singular importance in sparse linear algebra. In this paper we discuss data structures and algorithms for SpMV that are efficiently implemented on the CUDA platform for the fine-grained parallel architecture of the GPU. Given the memory-bound nature of SpMV, we emphasize memory bandwidth efficiency and compact storage formats. We consider a broad spectrum of sparse matrices, from those that are well-structured and regular to highly irregular matrices with large imbalances in the distribution of nonzeros per matrix row. We develop methods to exploit several common forms of matrix structure while offering alternatives which accommodate greater irregularity. On structured, grid-based matrices we achieve performance of 36 GFLOP/s in single precision and 16 GFLOP/s in double precision on a GeForce GTX 280 GPU. For unstructured finite-element matrices, we observe performance in excess of 15 GFLOP/s and 10 GFLOP/s in single and double precision respectively. These results compare favorably to prior state-of-the-art studies of SpMV methods on conventional multicore processors. Our double precision SpMV performance is generally two and a half times that of a Cell BE with 8 SPEs and more than ten times greater than that of a quad-core Intel Clovertown system. | |

|
N. Satish, M. Harris, and M. Garland.
Designing efficient sorting algorithms for manycore GPUs.
NVIDIA Technical Report NVR-2008-001, September 2008
[PDF]
We describe the design of high-performance parallel radix sort and merge sort routines for manycore GPUs, taking advantage of the full programmability offered by CUDA. Our radix sort is the fastest GPU sort reported in the literature, and is up to 4 times faster than the graphics-based GPUSort. It is also highly competitive with CPU implementations, being up to 3.5 times faster than comparable routines on an 8-core 2.33 GHz Intel Core2 Xeon system. Our merge sort is the fastest published comparison-based GPU sort and is also competitive with multi-core routines. To achieve this performance, we carefully design our algorithms to expose substantial fine-grained parallelism and decompose the computation into independent tasks that perform minimal global communication. We exploit the high-speed on-chip shared memory provided by NVIDIA’s Tesla architecture and efficient data-parallel primitives, particularly parallel scan. While targeted at GPUs, these algorithms should also be well-suited for other manycore processors | |
|
Y. Jia, J. Hoberock, M. Garland, and J. C. Hart.
On the visualization of social and other scale-free networks.
IEEE Transactions on Visualization and Computer Graphics,
14(6), Proc. Infovis 2008, November 2008, pp. 1285-1292.
[PDF]
This paper proposes novel methods for visualizing specifically the large power-law graphs that arise in sociology and the sciences. In such cases a large portion of edges can be shown to be less important and removed while preserving component connectedness and other features (e.g., cliques) to more clearly reveal the network’s underlying connection pathways. This simplification approach deterministically filters (instead of clustering) the graph to retain important node and edge semantics, and works both automatically and interactively. The improved graph filtering and layout is combined with a novel computer graphics anisotropic shading of the dense crisscrossing array of edges to yield a full social network and scale-free graph visualization system. Both quantitative analysis and visual results demonstrate the effectiveness of this approach. | |

|
A. Godiyal, J. Hoberock, M. Garland, and J. C. Hart
Rapid multipole graph drawing on the GPU.
Proc. Graph Drawing 2008, September 2008. To appear.
[PDF]
As graphics processors become powerful, ubiquitous and easier to program, they have also become more amenable to general purpose high-performance computing, including the computationally expensive task of drawing large graphs. This paper describes a new parallel analysis of the multipole method of graph drawing to support its efficient GPU implementation. We use a variation of the Fast Multipole Method to estimate the long distance repulsive forces in force directed layout. We support these multipole computations efficiently with a k-d tree constructed and traversed on the GPU. The algorithm achieves impressive speedup over previous CPU and GPU methods, drawing graphs with hundreds of thousands of vertices within a few seconds via CUDA on an NVIDIA GeForce 8800 GTX. | |

|
M. Garland, S. Le Grand, J. Nickolls, J. Anderson, J. Hardwick,
S. Morton, E. Phillips, Y. Zhang, and V. Volkov.
Parallel computing experiences with CUDA.
IEEE Micro, 28(4):13-27, July/August, 2008.
[Online]
The CUDA programming model provides a straightforward means of describing inherently parallel computations, and NVIDIA’s Tesla GPU architecture delivers high computational throughput on massively parallel problems. This article surveys experiences gained in applying CUDA to a diverse set of problems and the parallel speedups over sequential codes running on traditional CPU architectures attained by executing key computations on the GPU. | |

|
J. Nickolls, I. Buck, M. Garland, and K. Skadron.
Scalable parallel programming with CUDA.
Queue 6, 2 (Mar. 2008), 40-53.
[Online]
The advent of multicore CPUs and manycore GPUs means that mainstream processor chips are now parallel systems. Furthermore, their parallelism continues to scale with Moore’s law. The challenge is to develop mainstream application software that transparently scales its parallelism to leverage the increasing number of processor cores, much as 3D graphics applications transparently scale their parallelism to manycore GPUs with widely varying numbers of cores. | |

|
S. Kircher and M. Garland.
Free-form motion processing.
ACM Transactions on Graphics, 27(2):1-13, April 2008.
[PDF]
[Movie (MP4)]
[Movie (WMV)]
Motion is the center of attention in many applications of computer graphics. Skeletal motion for articulated characters can be processed and altered in a great variety of ways to increase the versatility of each motion clip. However, analogous techniques have not yet been developed for free-form deforming surfaces like cloth and faces. Given the time consuming nature of producing each free-form motion clip, the ability to alter and reuse free-form motion would be very desirable. We present a novel method for processing free-form motion that opens up a broad range of possible motion alterations, including motion blending, keyframe insertion, and temporal signal processing. Our method is based on a simple, yet powerful, differential surface representation that is invariant under rotation and translation, and which is well suited for surface editing in both space and time. | |

|
S. Dong and M. Garland.
Iterative methods for improving mesh parameterizations.
IEEE Shape Modeling International 2007, To appear.
[PDF]
We present two complementary methods for automatically improving mesh parameterizations and demonstrate that they provide a very desirable combination of efficiency and quality. First, we describe a new iterative method for constructing quasi-conformal parameterizations with free boundaries. We formulate the problem as fitting the coordinate gradients to two guidance vector fields of equal magnitude that are everywhere orthogonal. In only one linear step, our method efficiently generates parameterizations with natural boundaries from those with convex boundaries. If repeated until convergence, it produces the unique global minimizer of the Dirichlet energy. Next, we introduce a new non-linear optimization framework that can rapidly reduce interior distortion under a variety of metrics. By iteratively solving linear systems, our algorithm converges to a high quality, low distortion parameterization in very few iterations. The two components of our system are effective both in combination or when used independently. | |
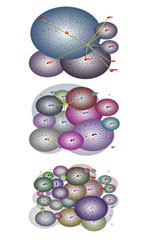
|
G. Kumar and M. Garland.
Visual exploration of complex time-varying graphs.
IEEE Transactions on Visualization and Computer Graphics,
Proceedings of InfoVis 2006, To appear.
[PDF]
[Movie]
Many graph drawing and visualization algorithms, such as force-directed layout and line-dot rendering, work very well on relatively small and sparse graphs. However, they often produce extremely tangled results and exhibit impractical running times for highly non-planar graphs with large edge density. And very few graph layout algorithms support dynamic time-varying graphs; applying them independently to each frame produces distracting temporally incoherent visualizations. We have developed a new visualization technique based on a novel approach to hierarchically structuring dense graphs via stratification. Using this structure, we formulate a hierarchical force-directed layout algorithm that is both efficient and produces quality graph layouts. The stratification of the graph also allows us to present views of the data that abstract away many small details of its structure. Rather than displaying all edges and nodes at once, resulting in a convoluted rendering, we present an interactive tool that filters edges and nodes using the graph hierarchy and allows users to drill down into the graph for details. Our layout algorithm also accommodates time-varying graphs in a natural way, producing a temporally coherent animation that can be used to analyze and extract trends from dynamic graph data. For example, we demonstrate the use of our method to explore financial correlation data for the U.S. stock market in the period from 1990 to 2005. The user can easily analyze the time-varying correlation graph of the market, uncovering information such as market sector trends, representative stocks for portfolio construction, and the interrelationship of stocks over time. | |
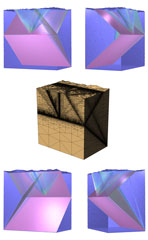
|
Y. Zhou and M. Garland.
Interactive point-based rendering of higher-order tetrahedral data.
IEEE Transactions on Visualization and Computer Graphics,
Proceedings of Visualization 2006, To appear.
[PDF]
Computational simulations frequently generate solutions defined over very large tetrahedral volume meshes containing many millions of elements. Furthermore, such solutions may often be expressed using non-linear basis functions. Certain solution techniques, such as discontinuous Galerkin methods, may even produce non-conforming meshes. Such data is difficult to visualize interactively, as it is far too large to fit in memory and many common data reduction techniques, such as mesh simplification, cannot be applied to non-conforming meshes. We introduce a point-based visualization system for interactive rendering of large, potentially non-conforming, tetrahedral meshes. We propose methods for adaptively sampling points from non-linear solution data and for decimating points at run time to fit GPU memory limits. Because these are streaming processes, memory consumption is independent of the input size. We also present an order-independent point rendering method that can efficiently render volumes on the order of 20 million tetrahedra at interactive rates. | |

|
S. Kircher and M. Garland.
Editing arbitrarily deforming surface animations.
ACM Transactions on Graphics,
Proceedings of SIGGRAPH 2006, To appear.
[PDF]
Deforming surfaces, such as cloth, can be generated through physical simulation, morphing, and even video capture. Such data is currently very difficult to alter after the generation process is complete, and data generated for one purpose generally cannot be adapted to other uses. Such adaptation would be extremely useful, however. Being able to take cloth captured from a flapping flag and attach it to a character to make a cape, or enhance the wrinkles on a simulated garment, would greatly enhance the usability and re-usability of deforming surface data. In addition, it is often necessary to cleanup or “tweak” simulation results. Doing this by editing each frame individually is a very time consuming and tedious process. Extensive research has investigated how to edit and re-use skeletal motion capture data, but very little has addressed completely non-rigid deforming surfaces. We have developed a novel method that now makes it easy to edit such arbitrary deforming surfaces. Our system enables global signal processing, direct manipulation, multiresolution embossing, and constraint editing on arbitrarily deforming surfaces, such as simulated cloth, motion-captured cloth, morphs, and other animations. The foundation of our method is a novel time-varying multiresolution transform, which adapts to the changing geometry of the surface in a temporally coherent manner. | |
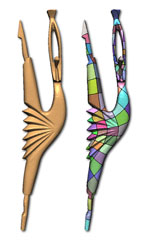
|
S. Dong, P-T. Bremer, M. Garland, V. Pascucci, and J. C. Hart.
Spectral surface quadrangulation.
ACM Transactions on Graphics,
Proceedings of SIGGRAPH 2006, To appear.
[PDF]
Resampling raw surface meshes is one of the most fundamental operations used by nearly all digital geometry processing systems. The vast majority of this work has focused on triangular remeshing, yet quadrilateral meshes are preferred for many surface PDE problems, especially fluid dynamics, and are best suited for defining Catmull-Clark subdivision surfaces. We describe a fundamentally new approach to the quadrangulation of manifold polygon meshes using Laplacian eigenfunctions, the natural harmonics of the surface. These surface functions distribute their extrema evenly across a mesh, which connect via gradient flow into a quadrangular base mesh. An iterative relaxation algorithm simultaneously refines this initial complex to produce a globally smooth parameterization of the surface. From this, we can construct a well-shaped quadrilateral mesh with very few extraordinary vertices. The quality of this mesh relies on the initial choice of eigenfunction, for which we describe algorithms and hueristics to efficiently and effectively select the harmonic most appropriate for the intended application. | |

|
S. Zelinka and M. Garland.
Surfacing by numbers.
Graphics Interface 2006,
To appear.
[PDF]
We present a novel technique for surface modelling by example called surfacing by numbers. Our system allows easy detail reuse from existing 3D models or images. The user selects a source region and a target region, and the system transfers detail from the source to the target. The source may be elsewhere on the target surface, on another surface altogether, or even part of an image. As transfer is formulated as synthesis with a novel surface-based adaptation of graph cuts, the source and target regions need not match in size or shape, and details can be geometric, textural or even user-defined in nature. A major contribution of our work is our fast, graph cut-based interactive surface segmentation algorithm. Unlike approaches based on scissoring, the user loosely strokes within the body of each desired region, and the system computes optimal boundaries between regions via minimum-cost graph cut. Thus, less precision is required, the amount of interaction is unrelated to the complexity of the boundary, and users do not need to search for a view of the model in which a cut can be made. | |

|
S. Atlan and M. Garland.
Interactive multiresolution editing and display of large terrains.
Computer Graphics Forum, 25(2):211-224, June 2006.
[Article]
In recent years, many systems have been developed for the real-time display of very large terrains. While many of these techniques combine high quality rendering with impressive performance, most make the fundamental assumption that the terrain is represented by a fixed height map that cannot be altered at runtime. Such systems frequently rely on extensive preprocessing of the raw terrain data. They are mostly designed for maximum performance. Consequently, these techniques are ill-suited for the many applications such as geological simulations and games in which terrain surfaces must be altered interactively. We present a two-component system that can achieve real-time view-dependent rendering while allowing on-line multiresolution alterations of a large terrain. Our fundamental height map representation is a wavelet quadtree hierarchy, allowing one to easily apply arbitrary multiresolution edits to the terrain. Our display algorithm extracts a view-dependent approximation of the terrain from the wavelet quadtree in real-time. The algorithm dynamically alters this approximation based on any ongoing edits. To allow for flexibility and to limit performance loss, the two components of this system have been designed to be as independent as possible. | |

|
S. Kircher and M. Garland.
Progressive Multiresolution Meshes for Deforming Surfaces.
ACM/Eurographics Symposium on Computer Animation,
pp. 191–200, 2005.
[PDF]
[Color plate]
[Movie (53MB MPEG4)]
Time-varying surfaces are ubiquitous in movies, games, and scientific applications. For reasons of efficiency and simplicity of formulation, these surfaces are often generated and represented as dense polygonal meshes with static connectivity. As a result, such deforming meshes often have a tremendous surplus of detail, with many more vertices and polygons than necessary for any given frame. An extensive amount of work has addressed the issue of simplifying a static mesh; however, these methods are inadequate for time-varying surfaces when there is a high degree of non-rigid deformation. We thus propose a new multiresolution representation for deforming surfaces that, together with our dynamic improvement scheme, provides high quality surface approximations at any level-of-detail, for all frames of an animation. Our algorithm also gives rise to a new progressive representation for time-varying multiresolution hierarchies, consisting of a base hierarchy for the initial frame and a sequence of update operations for subsequent frames. We demonstrate that this provides a very effective means of extracting static or view-dependent approximations for a deforming mesh over all frames of an animation. | |
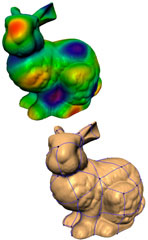
|
S. Dong, P.-T. Bremer, M. Garland, V. Pascucci, and J. C. Hart.
Quadrangulating a Mesh using Laplacian Eigenvectors.
Technical Report UIUCDCS-R-2005-2583, June 2005.
[Tech Rept]
Resampling raw surface meshes is one of the most fundamental operations used by nearly all digital geometry processing systems. The vast majority of work in the past has focused on triangular remeshing; the equally important problem of resampling surfaces with quadrilaterals has remained largely unaddressed. Despite the relative lack of attention, the need for quality quadrangular resampling methods is of central importance in a number of important areas of graphics. Quadrilaterals are the preferred primitive in many cases, such as Catmull-Clark subdivision surfaces, fluid dynamics, and texture atlasing. We propose a fundamentally new approach to the problem of quadrangulating manifold polygon meshes. By applying a Morse-theoretic analysis to the eigenvectors of the mesh Laplacian, we have developed an algorithm that can correctly quadrangulate any manifold, no matter its genus. Because of the properties of the Laplacian operator, the resulting quadrangular patches are well-shaped and arise directly from intrinsic properties of the surface, rather than from arbitrary heuristics. We demonstrate that this quadrangulation of the surface provides a base complex that is well-suited to semi-regular remeshing of the initial surface into a fully conforming mesh composed exclusively of quadrilaterals. | |

|
S. Zelinka, H. Fang, M. Garland, and J. Hart.
Interactive Material Replacement in Photographs.
Graphics Interface 2005, pp. 227–232, 2005.
[PDF]
[Movie]
Material replacement has wide application throughout the entertainment industry, particularly for postproduction make-up application or wardrobe adjustment. More generally, any low-cost mock-up object can be processed to have the appearance of expensive, high-quality materials. We demonstrate a new system that allows fast, intuitive material replacement in photographs. We extend recent work in object selection and fast texture synthesis, as well as develop a novel approach to shape-from-shading capable of handling objects with albedo changes. Each component of our system runs with interactive speed, allowing for easy experimentation and refinement of results. | |
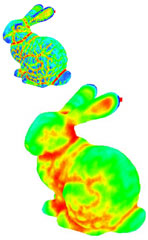
|
T. Gatzke, C. Grimm, M. Garland, and S. Zelinka.
Curvature Maps for Local Shape Comparison.
Shape Modeling International, pp. 244–256, 2005.
[PDF]
The ability to identify similarities between shapes is important for applications such as medical diagnosis, object registration and alignment, and shape retrieval. In this paper we present a method, which we call a Curvature Map, that uses surface curvature properties in a region around a point to create a unique signature for that point. These signatures can then be compared to determine the similarity of one point to another. To gather curvature information around a point we explore two techniques, rings (which use the local topology of the mesh) and Geodesic Fans (which trace geodesics along the mesh from the point). We explore a variety of comparison functions and provide experimental evidence for which ones provide the best discriminatory power. We show that Curvature Maps are both more robust and provide better discrimination than simply comparing the curvature at individual points. | |

|
Y. Kho and M. Garland.
Sketching mesh deformations.
Proceedings of the ACM Symposium on Interactive 3D Graphics,
pp. 147–154,
April 2005.
[PDF]
[Movie (high: 48 MB)]
[Movie (low: 16 MB)]
[Talk (19 MB QuickTime)]
Techniques for interactive deformation of unstructured polygon meshes are of fundamental importance to a host of applications. Most traditional approaches to this problem have emphasized precise control over the deformation being made. However, they are often cumbersome and unintuitive for non-expert users. In this paper, we present a system for interactively deforming unstructured polygon meshes that is very easy to use. The user interacts with the system by sketching curves in the image plane. A single stroke can define a free-form skeleton and the region of the model to be deformed. By sketching the desired deformation of this reference curve, the user can implicitly and intuitively control the deformation of an entire region of the surface. At the same time, the reference curve also provides a basis for controlling additional parameters, such as twist and scaling. We demonstrate that our system can be used to interactively edit a variety of unstructured mesh models with very little effort. We also show that our formulation of the deformation provides a natural way to interpolate between character poses, allowing the user to generate simple key framed animations. | |
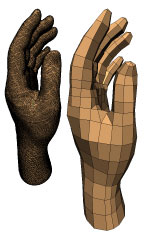
|
S. Dong, S. Kircher, and M. Garland.
Harmonic functions for quadrilateral remeshing of arbitrary manifolds.
Computer Aided Geometry Design,
Special Issue on Geometry Processing, 22(5):392–423, 2005.
[Preprint]
In this paper, we propose a new quadrilateral remeshing method for manifolds of arbitrary genus that is at once general, flexible, and efficient. Our technique is based on the use of smooth harmonic scalar fields defined over the mesh. Given such a field, we compute its gradient field and a second vector field that is everywhere orthogonal to the gradient. We then trace integral lines through these vector fields to sample the mesh. The two nets of integral lines together are used to form the polygons of the output mesh. Curvature-sensitive spacing of the lines provides for anisotropic meshes that adapt to the local shape. Our scalar field construction allows users to exercise extensive control over the structure of the final mesh. The entire process is performed without computing a parameterization of the surface, and is thus applicable to manifolds of any genus without the need for cutting the surface into patches. | |
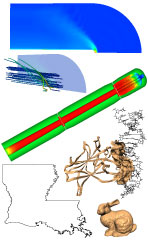
|
M. Garland and Y. Zhou.
Quadric-based Simplification in any Dimension.
ACM Transactions on Graphics, 24(2), April 2005.
Draft preprint available as Tech Report UIUCDCS-R-2004-2450.
[Tech Rept]
We present a new method for simplifying simplicial complexes of any type embedded in Euclidean spaces of any dimension. At the heart of this system is a novel generalization of the quadric error metric used in surface simplification. We demonstrate that our generalized simplification system can produce high quality approximations of plane and space curves, triangulated surfaces, and tetrahedralized volume data. Our method is both efficient and easy to implement. It is capable of processing complexes of arbitrary topology, including non-manifolds, and can preserve intricate boundaries. | |
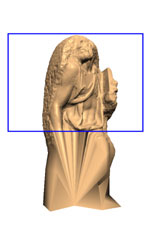
|
E. Shaffer and M. Garland.
A multiresolution representation for massive meshes.
IEEE Transactions on Visualization and Computer Graphics,
11(2):139–148, March/April 2005.
[PDF]
We present a new external memory multiresolution surface
representation for massive polygonal meshes. Previous methods for
building such data structures have relied on resampled surface data
or employed memory intensive construction algorithms that do not
scale well. Our proposed representation combines efficient access to
a rich set of sampled surface data with access to the original
surface. The construction algorithm for the surface representation
exhibits memory requirements that are insensitive to the size of the
input mesh, allowing it to process meshes containing hundreds of
millions of polygons. The multiresolution nature of the surface
representation has allowed us to develop efficient algorithms for
view-dependent rendering, approximate collision detection, and
adaptive simplification of massive meshes. The empirical performance
of these algorithms demonstrates that the underlying data structure
is a powerful and flexible tool for operating on massive geometric
data.
| |

|
S. Zelinka and M. Garland.
Mesh Modelling with Curve Analogies,
Proceedings of Pacific Graphics 2004, pp. 94–98, October 2004.
[PDF]
[Movie]
[Slides]
Modelling by analogy has become a powerful paradigm for editing images. Using a pair of before- and after-example images of a transformation, a system that models by analogy produces analogous transformations on arbitrary new images. This paper brings the expressive power of modelling by analogy to meshes. To avoid the difficulty of specifying fully 3D example meshes, we use Curve Analogies to produce changes in meshes. We apply analogies to families of curves on an object’s surface, and use the filtered curves to drive a transformation of the object. We demonstrate a range of filters, from simple local feature elimination/addition, to more general frequency enhancement filters. | |
|
Y. Zhou, M. Garland, and R. Haber.
Pixel-Exact Rendering of Spacetime Finite Element Solutions.
Proceedings of IEEE Visualization 2004,
pp. 425–432, October 2004.
[PDF]
[Movie (low: 7MB)]
[Movie (high: 23MB)]
Computational simulation of time-varying physical processes is of fundamental importance for many scientific and engineering applications. Most frequently, time-varying simulations are performed over multiple spatial grids at discrete points in time. In this paper, we investigate a new approach to time-varying simulation: spacetime discontinuous Galerkin finite element methods. The result of this simulation method is a simplicial tessellation of spacetime with per-element polynomial solutions for physical quantities such as strain, stress, and velocity. To provide accurate visualizations of the resulting solutions, we have developed a method for per-pixel evaluation of solution data on the GPU. We demonstrate the importance of per-pixel rendering versus simple linear interpolation for producing high quality visualizations. We also show that our system can accommodate reasonably large datasets — spacetime meshes containing up to 6 million tetrahedra are not uncommon in this domain. | |

|
S. Zelinka and M. Garland.
Jump Map-Based Interactive Texture Synthesis.
ACM Transactions on Graphics, 23(5), October 2004.
[Pre-print]
We present techniques for accelerated texture synthesis from example images. The key idea of our approach is to divide the task into two phases: analysis, and synthesis. During the analysis phase, which is performed once per sample texture, we generate a jump map. Using the jump map, the synthesis phase is capable of synthesizing texture similar to the analyzed example at interactive rates. We describe two such synthesis phase algorithms: one for creating images, and one for directly texturing manifold surfaces. We produce texture images at rates comparable to the fastest alternative algorithms, and produce textured surfaces an order of magnitude faster than current alternative approaches. We further develop a new, faster patch-based algorithm for image synthesis which improves the quality of our results on ordered textures. We show how controls used for specifying texture synthesis on surfaces may be used on images as well, allowing interesting new image-based effects, and highlight modelling applications enabled by the speed of our approach. | |

|
A. Y. Wu, M. Garland, and J. Han.
Mining scale-free networks using geodesic clustering.
Proceedings of the 10th ACM SIGKDD Intl. Conference,
pp.719–724, August 2004.
[PDF]
Many real-world graphs have been shown to be scale-free – vertex degrees follow power law distributions, vertices tend to cluster, and the average length of all shortest paths is small. We present a new model for understanding scale-free networks based on multilevel geodesic approximation, using a new data structure called a multilevel mesh. Using this multilevel framework, we propose a new kind of graph clustering that we use for data reduction of very large graph systems such as social, biological, or electronic networks. Finally, we apply our algorithms to real-world social networks and protein interaction graphs to show that they can reveal knowledge embedded in underlying graph structures. We also demonstrate how our data structures can be used to quickly answer approximate distance and shortest path queries on scale-free networks. | |

|
S. Zelinka and M. Garland.
Similarity-based surface modelling using geodesic fans.
Proc. of the 2nd Eurographics Symposium on Geometry
Processing, pp. 209-218, July 2004.
[PDF]
[Movie]
[Talk]
[SIGGRAPH
2004 Sketch]
We present several powerful new techniques for similarity-based modelling of surfaces using geodesic fans, a new framework for local surface comparison. Similarity-based surface modelling provides intelligent surface manipulation by simultaneously applying a modification to all similar areas of the surface. We demonstrate similarity-based painting, deformation, and filtering of surfaces, and show how to vary our similarity measure to encompass geometry, textures, or other arbitrary signals. The basis for our system, geodesic fans are neighbourhoods uniformly sampled in the geodesic polar coordinates of a point on a surface. We show how geodesic fans offer fast approximate alignment and comparison of surface neighbourhoods using simple spoke reordering. As geodesic fans offer a a structurally equivalent definition of neighbourhoods everywhere on a surface, they are amenable to standard acceleration techniques and are well-suited to extending image domain methods for modelling by example to surfaces. | |

|
X. Ni, M. Garland, and J. C. Hart.
Fair Morse functions for extracting the
topological structure of a surface mesh.
ACM Transactions on Graphics 23(3):613–622,
Proceedings of SIGGRAPH 2004, August 2004.
[PDF]
Morse theory reveals the topological structure of a shape based on the critical points of a real function over the shape. A poor choice of this real function can lead to a complex configuration of an unnecessarily high number of critical points. This paper solves a relaxed form of Laplace’s equation to find a “fair” Morse function with a user-controlled number and configuration of critical points. When the number is minimal, the resulting Morse complex cuts the shape into a disk. Specifying additional critical points at surface features yields a base domain that better represents the geometry and shares the same topology as the original mesh, and can also cluster a mesh into approximately developable patches. We make Morse theory on meshes more robust with teflon saddles and flat edge collapses, and devise a new “intermediate value propagation” multigrid solver for finding fair Morse functions that runs in provably linear time. | |
|
R. Abedi, S.-H. Chung, J. Erickson, Y. Fan, M. Garland, D. Guoy, R.
Haber, J. Sullivan, S. Thite, and Y. Zhou.
Spacetime meshing with adaptive refinement and coarsening.
Procceedings of the 20th Annual ACM Symposium on Computational
Geometry, pp. 300-309, June 2004.
[PDF]
We propose a new algorithm for constructing finite-element meshes
suitable for spacetime discontinuous Galerkin solutions of linear
hyperbolic PDEs. Given a triangular mesh M of some planar domain and a
target time value T, our method constructs a tetrahedral mesh of the
spacetime domain M x [0,T], in constant time per element, using an
advancing front method. Elements are added to the evolving mesh in small
patches by moving a vertex of the front forward in time. Spacetime
discontinuous Galerkin methods allow the numerical solution within each
patch to be computed as soon as the patch is created. Our algorithm
employs new mechanisms for adaptively coarsening and refining the front
in response to a posteriori error estimates returned by the numerical
code. A change in the front induces a corresponding re nement or
coarsening of future elements in the spacetime mesh. Our algorithm
adapts the duration of each element to the local quality, feature size,
and degree of refinement of the underlying space mesh. We directly
exploit the ability of discontinuous Galerkin methods to accommodate
discontinuities in the solution fields across element boundaries.
| |

|
S. Zelinka and M. Garland.
Interactive Texture Synthesis on Surfaces Using Jump Maps.
Eurographics Symposium on Rendering 2003, June 2003.
[PDF]
[Video]
We introduce a new method for fast texture synthesis on surfaces from examples. We generalize the image-based jump map texture synthesis algorithm, which partitions the task of texture synthesis into a slower analysis phase and a fast synthesis phase, by developing a new synthesis phase which works directly on arbitrary surfaces. Our method is one to two orders of magnitude faster than existing techniques, and does not generate any new texture images, enabling interactive applications for reasonably-sized meshes. This capability would be useful in many areas, including the texturing of dynamically-generated surfaces, interactive modelling applications, and rapid prototyping workflows. Our method remains simple to implement, assigning an offset in texture space to each edge of the mesh, followed by a walk over the mesh vertices to assign texture coordinates. A final step ensures each triangle receives consistent texture coordinates at its corners, and if available, texture blending can be used to improve the quality of results. | |

|
S. Zelinka and M. Garland.
Mesh Modelling with Curve Analogies,
SIGGRAPH 2003 Technical Sketches.
[PDF]
[Movie]
[Talk]
Modelling by analogy has become a powerful paradigm for editing images. Using a pair of before- and after-example images of a transformation, a system that models by analogy produces analogous transformations on arbitrary new images. This paper brings the expressive power of modelling by analogy to meshes. To avoid the difficulty of specifying fully 3D example meshes, we use Curve Analogies to produce changes in meshes. We apply analogies to families of curves on an object’s surface, and use the filtered curves to drive a transformation of the object. We demonstrate a range of filters, from simple local feature elimination/addition, to more general frequency enhancement filters. | |

|
Y. Kho and M. Garland.
User-Guided Simplification.
In Proceedings of ACM Symposium on Interactive 3D Graphics,
April 2003.
[PDF]
[Movie]
[Talk]
While many effective simplification algorithms have been developed, they often produce poor approximations when a model is simplified to very low level of detail. Furthermore, previous algorithms are not sensitive to semantic or high-level meanings of models. In this paper, we present a user-guided approach for mesh simplification processes to overcome such limitations. Our proposed method lets users selectively control the relative importance of different surface regions and preserve various features by imposing geometric constraints. Using our system, users can produce perceptually improved approximations with very little user effort. | |

|
M. Garland and E. Shaffer.
A Multiphase Approach to Efficient Surface Simplification.
In Proceedings of IEEE Visualization 2002, October 2002.
[PDF]
We present a new multiphase method for efficiently simplifying polygonal surface models of arbitrary size. It operates by combining an initial out-of-core uniform clustering phase with a subsequent in-core iterative edge contraction phase. These two phases are both driven by quadric error metrics, and quadrics are used to pass information about the original surface between phases. The result is a method that produces approximations of a quality comparable to quadric-based iterative edge contraction, but at a fraction of the cost in terms of running time and memory consumption. | |

|
S. Zelinka and M. Garland.
Towards Real-Time Texture Synthesis with the Jump Map.
Eurographics Workshop on Rendering 2002, June 2002.
[PDF]
[Talk]
While texture synthesis has been well-studied in recent years, real-time
techniques remain elusive. To help facilitate real-time texture
synthesis, we divide the task of texture synthesis into two phases: a
relatively slow analysis phase, and a real-time synthesis phase. Any
particular texture need only be analyzed once, and then an unlimited
amount of texture may be synthesized in real-time. Our analysis phase
generates a jump map, which stores for each input pixel a set of
matching input pixels (jumps). Texture synthesis proceeds in real-time
as a random walk through the jump map. Each new pixel is synthesized by
extending the patch of input texture from which one of its neighbours
was copied. Occasionally, a jump is taken through the jump map to begin
a new patch. Despite the method’s extreme simplicity, its speed and
output quality compares favourably with recent patch-based algorithms.
| |

|
S. Zelinka and M. Garland.
Permission Grids: Practical, Error-Bounded Simplification.
ACM Transactions on Graphics, 21(2), April 2002.
[PDF]
We introduce the permission grid, a spatial occupancy grid which can be used to guide almost any standard polygonal surface simplification algorithm into generating an approximation with a guaranteed geometric error bound. In particular, all points on the approximation are guaranteed to be within some user-specified distance from the original surface. Such bounds are notably absent from many current simplification methods, and are becoming increasingly important for applications in scientific computing and adaptive level of detail control. Conceptually simple, the permission grid defines a volume in which the approximation must lie, and does not permit the underlying simplification algorithm to generate approximations outside the volume. The permission grid makes three important, practical improvements over current error-bounded simplification methods. First, it works on arbitrary triangular models, handling all manners of mesh degeneracies gracefully. Further, the error tolerance may be easily expanded as simplification proceeds, allowing the construction of an error-bounded level of detail hierarchy with vertex correspondences among all levels of detail. And finally, the permission grid has a representation complexity independent of the size of the input model, and a small running time overhead, making it more practical and efficient than current methods with similar guarantees. | |
|
E. Shaffer and M. Garland.
Efficient Adaptive Simplification of Massive Meshes.
In Proceedings of IEEE Visualization 2001.
[PDF]
The growing availability of massive polygonal models, and the inability of most existing visualization tools to work with such data, has created a pressing need for memory efficient methods capable of simplifying very large meshes. In this paper, we present a method for performing adaptive simplification of polygonal meshes that are too large to fit in-core. Our algorithm performs two passes over an input mesh. In the first pass, the model is quantized using a uniform grid, and surface information is accumulated in the form of quadrics and dual quadrics. This sampling is then used to construct a BSP-Tree in which the partitioning planes are determined by the dual quadrics. In the final pass, the original vertices are clustered using the BSPTree, yielding an adaptive approximation of the original mesh. The BSP-Tree describes a natural simplification hierarchy, making it possible to generate a progressive transmission and construct levelof- detail representations. In this way, the algorithm provides some of the features associated with more expensive edge contraction methods while maintaining greater computational efficiency. In addition to performing adaptive simplification, our algorithm exhibits output-sensitive memory requirements and allows fine control over the size of the simplified mesh. | |
|
J. Ribelles, P. Heckbert, M. Garland, T. Stahovich, and V. Srivastava.
Finding and Removing Features from Polyhedra.
In Proceedings of ASME Design Engineering Technical
Conference, September 2001.
[PDF]
Geometric models of solids often contain small features that we would like to isolate and remove. Examples include bumps, holes, tabs, notches, and decorations. Feature removal can be desirable for numerous reasons, including economical meshing and finite element simulation, analysis of feature purpose, and compact shape representation. In thiswork, an algorithmis presented that inputs a polyhedral solid, identifies and ranks its candidate features, and outputs solid models of the feature and the original object with the feature removed. Ranking permits a user or higher level software to quickly find the most desirable features for the task at hand. Features are defined in terms of portions of the surface that are classified differently from the rest of the solid’s surface with respect to one or more split planes. This approach to feature definition is more general than many previous methods, and generalizes naturally to quadric surfaces and other implicit surfaces. | |
|
M. Garland, A. Willmott, and P. Heckbert.
Hierarchical Face Clustering on Polygonal Surfaces.
In Proceedings of ACM Symposium on Interactive 3D Graphics,
March 2001.
[PDF]
Many graphics applications, and interactive systems in particular, rely on hierarchical surface representations to efficiently process very complex models. Considerable attention has been focused on hierarchies of surface approximations and their construction via automatic surface simplification. Such representations have proven effective for adapting the level of detail used in real time display systems. However, other applications such as ray tracing, collision detection, and radiosity benefit from an alternative multiresolution framework: hierarchical partitions of the original surface geometry. We present a new method for representing a hierarchy of regions on a polygonal surface which partition that surface into a set of face clusters. These clusters, which are connected sets of faces, represent the aggregate properties of the original surface at different scales rather than providing geometric approximations of varying complexity. We also describe the combination of an effective error metric and a novel algorithm for constructing these hierarchies. | |

|
A. Willmott, P. Heckbert, and M. Garland.
Face cluster radiosity.
Eurographics Workshop on Rendering,
June 1999.
[PDF ]
[at CMU]
[Talk (html)]
An algorithm for simulating diffuse interreflection in complex three dimensional scenes is described. It combines techniques from hierarchical radiosity and multiresolution modelling. A new face clustering technique for automatically partitioning polygonal models is used. The face clusters produced group adjacent triangles with similar normal vectors. They are used during radiosity solution to represent the light reflected by a complex object at multiple levels of detail. Also, the radiosity method is reformulated in terms of vector irradiance and power. Together, face clustering and the vector formulation of radiosity permit large savings. Excessively fine levels of detail are not accessed by the algorithm during the bulk of the solution phase, greatly reducing its memory requirements relative to previous methods. Consequently, the costliest steps in the simulation can be made sub-linear in scene complexity. Using this algorithm, radiosity simulations on scenes of one million input polygons can be computed on a standard workstation. | |
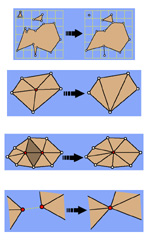
|
M. Garland.
Multiresolution Modeling: Survey & future opportunities.
Eurographics ‘99, State of the Art Report, September 1999.
[PDF]
[Talk (pdf)]
For twenty years, it has been clear that many datasets are excessively complex for applications such as real-time display, and that techniques for controlling the level of detail of models are crucial. More recently, there has been considerable interest in techniques for the automatic simplification of highly detailed polygonal models into faithful approximations using fewer polygons. Several effective techniques for the automatic simplification of polygonal models have been developed in recent years. This report begins with a survey of the most notable available algorithms. Iterative edge contraction algorithms are of particular interest because they induce a certain hierarchical structure on the surface. An overview of this hierarchical structure is presented,including a formulation relating it to minimum spanning tree construction algorithms. Finally, we will consider the most significant directions in which existing simplification methods can be improved, and a summary of other potential applications for the hierarchies resulting from simplification. | |
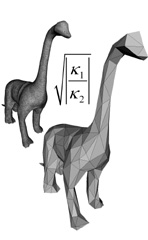
|
P. Heckbert and M. Garland.
Optimal Triangulation and Quadric-Based Surface Simplification.
Journal of Computational Geometry: Theory and Applications,
14(1-3), pp. 49-65, November 1999.
[PDF]
[Alternate]
Many algorithms for simplifying surface models have been proposed, but to date there has been little analysis of the approximations they produce. Previously we described an algorithm that simplifies polygonal models using a quadric error metric. This method is fast and produces high quality approximations in practice. Here we provide some theory to explain why the algorithm works as well as it does. Using methods from differential geometry and approximation theory, we show that in the limit as triangle area goes to zero on a differentiable surface, the quadric error is directly related to surface curvature. Also, in this limit, a triangulation that minimizes the quadric error metric achieves optimal triangle shape in that it minimizes the L2 geometric error. This work represents a new theoretical approach for the analysis of simplification algorithms. | |
|
Michael Garland.
Quadric-Based Polygonal Surface Simplification.
Ph.D. dissertation,
Computer Science Department,
Carnegie Mellon University, CMU-CS-99-105, May 1999.
[Online]
Many applications in computer graphics and related fields can benefit from automatic simplification of complex polygonal surface models. Applications are often confronted with either very densely over-sampled surfaces or models too complex for the limited available hardware capacity. An effective algorithm for rapidly producing high-quality approximations of the original model is a valuable tool for managing data complexity. In this dissertation, I present my simplification algorithm, based on iterative vertex pair contraction. This technique provides an effective compromise between the fastest algorithms, which often produce poor quality results, and the highest-quality algorithms, which are generally very slow. For example, a 1000 face approximation of a 100,000 face model can be produced in about 10 seconds on a PentiumPro 200. The algorithm can simplify both the geometry and topology of manifold as well as non-manifold surfaces. In addition to producing single approximations, my algorithm can also be used to generate multiresolution representations such as progressive meshes and vertex hierarchies for view-dependent refinement. The foundation of my simplification algorithm, is the quadric error metric which I have developed. It provides a useful and economical characterization of local surface shape, and I have proven a direct mathematical connection between the quadric metric and surface curvature. A generalized form of this metric can accommodate surfaces with material properties, such as RGB color or texture coordinates. I have also developed a closely related technique for constructing a hierarchy of well-defined surface regions composed of disjoint sets of faces. This algorithm involves applying a dual form of my simplification algorithm to the dual graph of the input surface. The resulting structure is a hierarchy of face clusters which is an effective multiresolution representation for applications such as radiosity. | |

|
M. Garland and P. Heckbert.
Simplifying Surfaces with Color and Texture using Quadric Error
Metrics.
In Proceedings of IEEE Visualization 98.
[PDF]
There are a variety of application areas in which there is a need for simplifying complex polygonal surface models. These models often have material properties such as colors, textures, and surface normals. Our surface simplification algorithm, based on iterative edge contraction and quadric error metrics, can rapidly produce high quality approximations of such models. We present a natural extension of our original error metric that can account for a wide range of vertex attributes. | |

|
M. Garland and P. Heckbert.
Surface Simplification Using Quadric Error Metrics.
In Proceedings of SIGGRAPH 97.
[PDF]
Many applications in computer graphics require complex, highly detailed models. However, the level of detail actually necessary may vary considerably. To control processing time, it is often desirable to use approximations in place of excessively detailed models. We have developed a surface simplification algorithm which can rapidly produce high quality approximations of polygonal models. The algorithm uses iterative contractions of vertex pairs to simplify models and maintains surface error approximations using quadric matrices. By contracting arbitrary vertex pairs (not just edges), our algorithm is able to join unconnected regions of models. This can facilitate much better approximations, both visually and with respect to geometric error. In order to allow topological joining, our system also supports non-manifold surface models. | |

|
P. Heckbert and M. Garland.
Survey of Polygonal Surface Simplification Algorithms.
In SIGGRAPH 97 Course Notes: Multiresolution Surface
Modeling.
[PDF]
This paper surveys methods for simplifying and approximating polygonal surfaces. Apolygonal surface is a piecewiselinear surface in 3-D defined by a set of polygons; typically a set of triangles. Methods from computer graphics, computer vision, cartography, computational geometry, and other fields are classified, summarized, and compared both practically and theoretically. The surface types range from height fields (bivariate functions), to manifolds, to nonmanifold self-intersecting surfaces. Piecewise-linear curve simplification is also briefly surveyed. | |

|
M. Garland and P. Heckbert.
Fast Polygonal Approximation of Terrains and Height Fields.
Technical Report CMU-CS-95-181. Also appears in
SIGGRAPH 96 Visual Proceedings: Technical Sketches.
[PS +
color plate]
[PDF]
Several algorithms for approximating terrains and other height fields using polygonal meshes are described, compared, and optimized. These algorithms take a height field as input, typically a rectangular grid of elevation data H(x,y), and approximate it with a mesh of triangles, also known as a triangulated irregular network, or TIN. The algorithms attempt to minimize both the error and the number of triangles in the approximation. Applications include fast rendering of terrain data for flight simulation and fitting of surfaces to range data in computer vision. The methods can also be used to simplify multi-channel height fields such as textured terrains or planar color images. The most successful method we examine is the greedy insertion algorithm. It begins with a simple triangulation of the domain and, on each pass, finds the input point with highest error in the current approximation and inserts it as a vertex in the triangulation. The mesh is updated either with Delaunay triangulation or with data-dependent triangulation. Most previously published variants of this algorithm had expected time cost of O(mn) or O(n log m + m^2), where n is the number of points in the input height field and m is the number of vertices in the triangulation. Our optimized algorithm is faster, with an expected cost of O((m+n)log m). On current workstations, this allows one million point terrains to be simplified quite accurately in less than a minute. We are releasing a C++ implementation of our algorithm. | |

|
P. Heckbert and M. Garland.
Multiresolution Modeling for Fast Rendering.
In Proceedings of Graphics Interface ‘94.
[Paper with corrections]
[Errata for printed version]
Three dimensional scenes are typically modeled using a single, fixed resolution model of each geometric object. Renderings of such a model are often either slow or crude, however: slow for distant objects, where the chosen detail level is excessive, and crude for nearby objects, where the detail level is insufficient. What is needed is a multiresolution model that represents objects at multiple levels of detail. With a multiresolution model, a rendering program can choose the level of detail appropriate for the object’s screen size so that less time is wasted drawing insignificant detail. The principal challenge is the development of algorithms that take a detailed model as input and automatically simplify it, while preserving appearance. Multiresolution techniques can be used to speed many applications, including real time rendering for architectural and terrain simulators, and slower, higher quality rendering for entertainment and radiosity. This paper surveys existing multiresolution modeling techniques and speculates about what might be possible in the future. | |